Wie erkennen Tools KI-Texte? Ein Blick hinter die Kulissen der Detektor-Software
Ein durchschnittlicher KI-Detektor liegt bei gut geschriebenen Texten häufiger falsch, als seine Entwickler öffentlich zugeben. Das ist kein Zufall — es ist ein strukturelles Problem, das direkt mit der Funktionsweise dieser Software zusammenhängt. Wer verstehen will, warum solche Tools manchmal Shakespeares Prosa als 'KI-generiert' einstufen, muss einen Blick auf die Mechanismen dahinter werfen.

Was KI-Detektoren eigentlich messen — und was nicht
Perplexity und Burstiness: Die zwei Kernmetriken
Die meisten Detektoren arbeiten mit zwei zentralen Konzepten: Perplexity und Burstiness. Perplexity beschreibt, wie 'überraschend' ein Text für ein Sprachmodell ist — also wie unwahrscheinlich die gewählten Wörter und Satzstrukturen statistisch gesehen sind. Ein Sprachmodell wie GPT wählt bevorzugt Wörter mit hoher Wahrscheinlichkeit, was zu niedriger Perplexity führt.
Burstiness misst die Varianz in der Satzlänge. Menschen schreiben tendenziell unregelmäßiger: kurze Sätze wechseln sich mit langen ab, Gedanken brechen ab, Wiederholungen entstehen. KI-Modelle produzieren dagegen oft eine gleichmäßigere Rhythmik — nicht weil sie so programmiert wurden, sondern weil sie auf Basis statistischer Wahrscheinlichkeiten arbeiten.
Das klingt nach einer soliden Grundlage. Aber hier liegt das erste Problem: Akademisches Schreiben, Rechtsdokumente und technische Handbücher zeigen von Natur aus niedrige Perplexity und geringe Burstiness — weil Präzision und Konsistenz dort gefordert sind.
Niedrige Perplexity bedeutet nicht 'KI hat das geschrieben' — es bedeutet 'ein Sprachmodell hätte das genauso schreiben können.' Das ist ein fundamentaler Unterschied.
Wie ein Detektor intern trainiert wird
Detektor-Software wird typischerweise als binärer Klassifikator trainiert: menschlicher Text auf der einen Seite, KI-generierter Text auf der anderen. Das Modell lernt, Muster zu erkennen, die statistisch mit einer der beiden Kategorien korrelieren. Viele kommerzielle Tools wurden auf englischsprachigen Texten trainiert — was erklärt, warum ihre Trefferquote bei deutschen oder mehrsprachigen Inhalten deutlich schlechter ist.
Ein konkretes Beispiel: GPTZero, eines der bekanntesten Tools, wurde ursprünglich primär auf englischen akademischen Texten trainiert. Wer damit einen deutschen Fachaufsatz prüft, testet das Modell weit außerhalb seiner Trainingsverteilung.
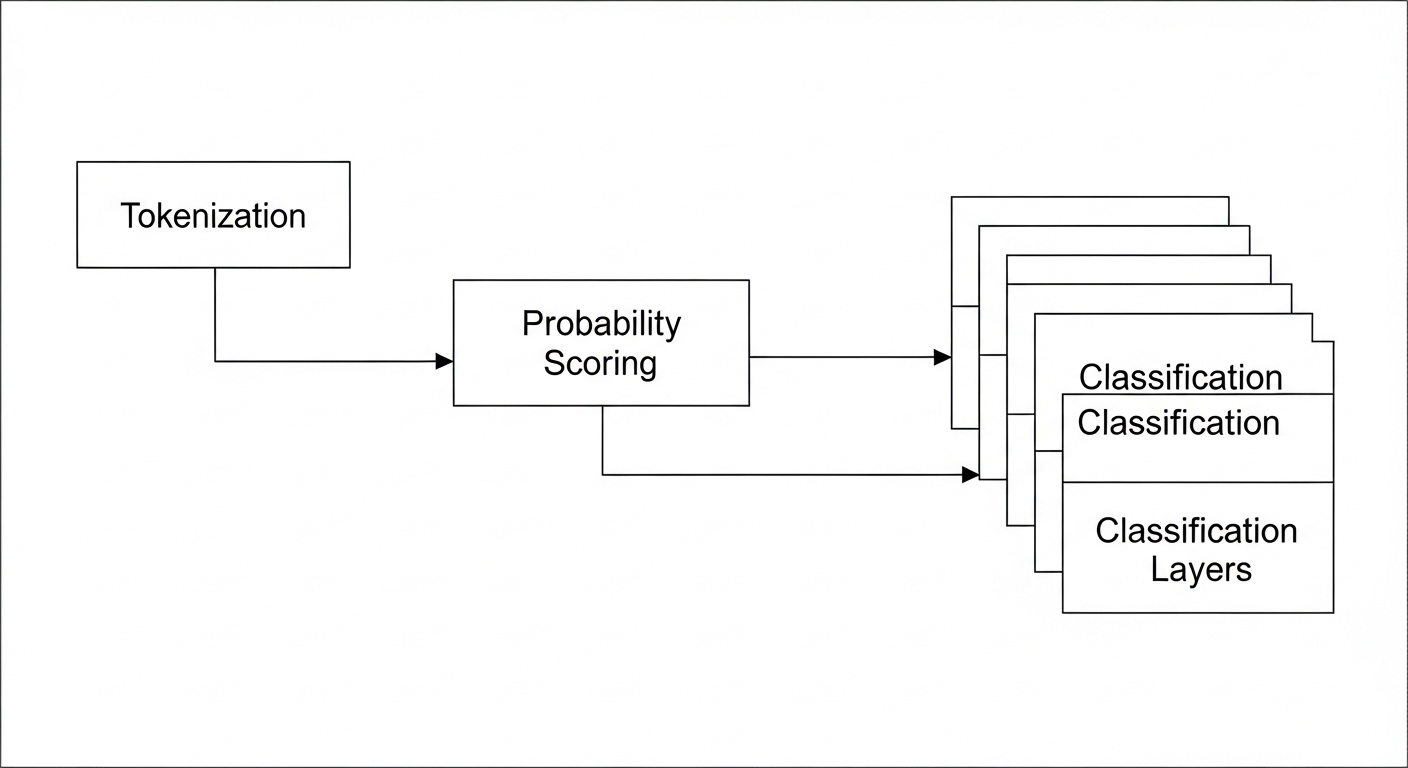
Wie der Erkennungsprozess Schritt für Schritt abläuft
Tokenisierung und Wahrscheinlichkeitsverteilung
Wenn ein Text in einen Detektor eingegeben wird, zerlegt das System ihn zunächst in Tokens — das sind Wortfragmente oder ganze Wörter, je nach Modell. Für jeden Token berechnet das System, wie wahrscheinlich er an dieser Stelle in einem typischen KI-generierten Text aufgetaucht wäre. Diese Einzelwahrscheinlichkeiten werden aggregiert und ergeben einen Gesamtscore.
Manche Tools gehen einen Schritt weiter und verwenden sogenannte Watermarking-Erkennung. Einige KI-Systeme können ihre Ausgaben mit statistischen Mustern versehen — einer Art unsichtbaren Signatur im Wahrscheinlichkeitsraum der Tokens. Das ist technisch elegant, aber nur dann nützlich, wenn das erzeugende System tatsächlich Watermarking verwendet hat.
Ensemble-Ansätze und neuronale Klassifikatoren
Modernere Detektoren kombinieren mehrere Methoden gleichzeitig. Sie nutzen feinabgestimmte Sprachmodelle, die speziell darauf trainiert wurden, KI-Texte zu erkennen, und kombinieren diese mit regelbasierten Heuristiken. Das Ergebnis ist ein Ensemble-Ansatz, der robuster ist als ein einzelner Algorithmus — aber auch deutlich rechenintensiver.
Der Haken: Jedes Mal, wenn ein neues KI-Modell veröffentlicht wird, veraltet ein Teil des Detektor-Trainings. Die Detektoren laufen den Generatoren strukturell hinterher.
Warum Detektoren so häufig falsch liegen
Das Problem der Falsch-Positiven
Forscher haben wiederholt gezeigt, dass Texte von Nicht-Muttersprachlern überdurchschnittlich oft als KI-generiert eingestuft werden. Der Grund ist naheliegend: Wer in einer Fremdsprache schreibt, tendiert zu einfacheren Strukturen, häufigeren Wörtern und weniger idiomatischen Wendungen — genau die Merkmale, die Detektoren als 'KI-typisch' interpretieren.
Ein reales Beispiel aus dem akademischen Bereich: Mehrere Universitäten in den USA haben Studenten fälschlicherweise des Betrugs beschuldigt, weil Detektor-Tools ihre Hausarbeiten als KI-generiert markiert hatten. In einigen dokumentierten Fällen handelte es sich um internationale Studierende, deren Schreibstil schlicht präziser und weniger idiomatisch war als der ihrer Kommilitonen.
Kein kommerzieller KI-Detektor gibt derzeit eine Falsch-Positiv-Rate von null an — und wer behauptet, sein Tool sei 'nahezu fehlerfrei', sollte nach den Testbedingungen gefragt werden.
Paraphrasierung als einfache Umgehungsstrategie
Wer einen KI-generierten Text durch ein einfaches Paraphrasierungs-Tool schickt, kann die Erkennungsrate vieler Detektoren drastisch senken. Das liegt daran, dass Paraphrasierung die Oberflächenstruktur des Textes verändert, ohne den Inhalt zu berühren — und viele Detektoren primär auf Oberflächenmerkmalen operieren.
Das ist ein bisschen wie ein Sicherheitssystem, das nur auf Gesichtsformen reagiert, aber Verkleidungen nicht erkennt.

Was Detektoren wirklich leisten können — und wo ihre Grenzen liegen
Sinnvolle Einsatzszenarien
Trotz aller Einschränkungen sind Detektoren in bestimmten Kontexten nützlich. Bei der Massenprüfung von Inhalten — etwa in Content-Marketing oder SEO-Agenturen — können sie als erster Filter dienen, der offensichtlich maschinell generierte Texte herausfiltert. Kein Mensch kann tausende Artikel manuell prüfen.
Auch bei der Qualitätssicherung in Redaktionen haben manche Tools einen Platz gefunden — nicht als endgültiges Urteil, sondern als Hinweis, der eine manuelle Prüfung auslöst. Das ist der richtige Umgang: Detektor als Triage-Werkzeug, nicht als Richter.
Die strukturelle Grenze: Ein Wettrüsten ohne Ende
Das fundamentale Problem ist epistemischer Natur. KI-Modelle werden besser darin, menschlich klingende Texte zu erzeugen — und Detektoren werden besser darin, diese zu erkennen. Aber der Abstand zwischen beiden Seiten bleibt, weil Detektoren immer reaktiv sind. Sie können nur erkennen, was sie kennen.
(Opinion: Es ist fraglich, ob KI-Detektoren jemals zuverlässig genug sein werden, um als Beweismittel in akademischen oder rechtlichen Kontexten zu dienen. Die Fehlerquoten sind schlicht zu hoch, und die Konsequenzen für fälschlicherweise beschuldigte Personen sind real und schwerwiegend.)
Ein Detail, das in den meisten Übersichtsartikeln fehlt: Einige Detektoren verwenden sogenannte Log-Likelihood-Ratio-Tests — sie vergleichen nicht nur, wie wahrscheinlich ein Text unter einem KI-Modell ist, sondern wie viel wahrscheinlicher er unter dem KI-Modell ist als unter einem Referenzmodell für menschliches Schreiben. Das ist methodisch sauberer, aber auch anfälliger für Verteilungsverschiebungen, wenn sich Schreibstile verändern.

Häufig gestellte Fragen
Kann ein KI-Detektor wirklich zuverlässig zwischen Mensch und Maschine unterscheiden?
Nein — zumindest nicht mit der Zuverlässigkeit, die viele Nutzer erwarten. Aktuelle Tools erreichen in kontrollierten Tests oft hohe Trefferquoten, aber diese Tests spiegeln selten die Vielfalt realer Texte wider. Bei kurzen Texten, Fachtexten oder Texten von Nicht-Muttersprachlern steigt die Fehlerrate erheblich.
Macht es einen Unterschied, welches KI-Modell den Text erzeugt hat?
Ja, deutlich. Detektoren werden meist auf Texten bestimmter Modelle trainiert. Texte neuerer oder weniger verbreiteter Modelle werden häufiger übersehen, weil ihre statistischen Muster im Trainingsdatensatz des Detektors unterrepräsentiert sind. Das ist einer der Hauptgründe, warum Detektoren nach jedem großen Modell-Release an Genauigkeit verlieren.
Kann man einen Text so umschreiben, dass er nicht mehr erkannt wird?
In den meisten Fällen ja. Einfaches Paraphrasieren, das Hinzufügen persönlicher Anekdoten oder das bewusste Einbauen ungewöhnlicher Formulierungen senkt die Erkennungsrate vieler Tools erheblich. Das zeigt, dass aktuelle Detektoren eher Oberflächenmerkmale als tiefere semantische Strukturen messen.
Was bleibt, ist eine unbequeme Erkenntnis: Die Frage 'Hat ein Mensch oder eine KI das geschrieben?' lässt sich technisch möglicherweise nie mit der Sicherheit beantworten, die wir uns wünschen — weil Sprache selbst kein eindeutiges Herkunftssignal trägt. Ein Text ist ein Text. Wer ihn bewertet, muss das im Hinterkopf behalten.



Kommentare
Kommentar veröffentlichen